李巍 | 中国哲学:AI能做什么?——附赵汀阳《对〈中国哲学:AI能做什么?〉一文的审查报告》
点击次数: 更新时间:2026-04-07
【摘 要】与对人工智能进行外围的哲学反思不同,AI应用于哲学研究的可能方式需要进行实验性评估。评估选取的对象是中国哲学,因为在这一学科中曾经存在的合法性争议提供了一种视角,能使人清楚地看到“哲学是什么”与“哲学研究是什么”不是同一领域的问题:前者是哲学问题,后者则是如何“做哲学”的工程问题,因而与评估AI应用的目标有关。在现有条件下进行这一评估的方案是,从“思想建模”的角度说明面向中国思想的哲学研究中“AI能做什么”,并由此说明AI的应用虽未必改变对“哲学”的传统理解,却可能深刻影响“哲学研究”的未来形态,比如,AI可能真正强化哲学学科与实验科学的关联,同时可能大大弱化哲学研究与经验研究的分界。
【关键词】人工智能;语言模型;中国哲学;思想研究;计算哲学;

作者简介:李巍,哲学博士,博士生导师,成人视频 教授。主要从事早期中国思想研究,致力探讨中国古代说理思维与中国思想的现代表述。主要研究领域和方向:早期中国哲学、中国逻辑史
文章来源:《江海学刊》2026年第1期

本文旨在探讨人工智能在中国哲学研究中的应用。场景不同,这个问题可大可小。比如,就AI在各学科中日益广泛的应用与影响来说,本文要谈的实在是一个小问题,因为现代大学在知识生产上有明确的专业分工,所以中国哲学的研究是否需要AI,这个问题的意义与价值最多不会超出人文研究的范围。但是,对关切中国哲学未来走向的人,甚至对关切人文研究在未来学术版图中是否有位置的人,如何看待AI的应用又是个大问题。因为随着AI在非人文专业的广泛落地,可能逐渐显露出的一个朴素的事实是:传统人文研究不会因为AI的发展受到冲击,但与AI保持疏离,就会在未来装备AI的学科竞争中受到冲击,尤其是进一步拉大与工程科学、自然科学和社会科学在知识生产效率上的差距,并由此导致人文学科在未来的大学建制中处于更加弱势的地位。当然,在人文研究中引入宽泛意义上的数字技术已经颇有历史,但仍然是一个小众与非主流的学术领域;而对哲学研究来说,AI会对当下与未来产生何种影响,除了诉诸想象,始终是缺乏判断依据的问题。因为“依据”首先要从应用AI的工程实例来看,但哲学家们想的太多而做的太少。
为此,论文尝试以中国哲学为例来说明AI能做什么。但这个示例可能引起担忧,因为中国哲学曾遭遇所谓合法性质疑(比如,否认中国思想中有哲学,或反对用“哲学”称谓中国本土思想),那么在这种情况下再谈论AI的应用,会不会把本来就不清楚的问题变得更复杂呢?未必!因为来自中国思想的素材是否具有名为“哲学”的合法性,这个问题之所以是有争议的,正在于“中国哲学”这个概念实际被默认为中国思想中的哲学,也就是说,被当成对中国本土思想资源的一种类型描述——但这既不是唯一解,也不是正确解,因为无论赞同还是反对中国思想属于“哲学”,这些判断要有意义,前提是存在名为“中国哲学”的专业学科。因为询问中国思想中有无哲学,问的正是这门学科的研究对象(中国思想)是怎样的(有无哲学)。因此,合法性质疑的阴霾挥之不去,将使我们对一个确凿的事实视而不见,即中国哲学首先是一门学科,而且这就是“中国哲学是什么”的标准答案。否认这个标准答案的人,可以拒绝与之讨论合法性问题,因为如果不是为了界定中国哲学这门学科的研究对象是什么,就不会提出中国思想是不是哲学的问题,可见合法性质疑本身就不合法。但另一方面,承认中国哲学首先是一门学科,合法性质疑固然合法,却可以在学理上被消解掉。因为说中国哲学是一门学科,就是说这门学科不同于其他学科,是以哲学的方式研究中国思想——而要害在于,以哲学的方式研究中国思想,这并不蕴含研究对象本身必须能被称为“哲学”,因为现代学术的基本特征是只有专属某一学科的研究方式,没有专属某一学科的研究对象,所以,中国哲学这门学科研究的对象,即中国思想,其是或不是哲学,对于这门学科的知识生产并不重要。那么真正值得讨论的就不是合法性问题,而是对中国本土思想资源的研究,作为中国哲学的学科行为,能不能被视为一种哲学研究?其与文学研究、历史研究或其他学科研究有何区别?判断的标准是什么?
这些问题,不论如何回答,性质上是一个现代学科具有何种专业性的问题。但讨论中国思想是不是哲学,却把研究者的注意力从一种学术研究是不是“哲学研究”的专业性,转向了其研究对象是不是“哲学”的合法性。我的观点是,合法性之所以可争议,是因为它高度依赖人们对“哲学是什么”的不同理解,但这个问题至少在目前还没有标准答案。与此相反,关于“哲学研究”是什么,作为对学科行为的描述,则必须有标准的(至少是被广泛接受的)回答,否则就等于瓦解了哲学作为专业学科的专业性,也就否定了哲学在现代大学中的建制身份。所以,还是从学科的观点看,真正重要的不是“哲学是什么”,而是“哲学研究是什么”——前一个问题仅关涉哪一种类型的思想能被称为“哲学”的合法性,但后一问题完全不同,认为其关涉专业性,在于其询问的是哲学或中国哲学的“学科行为”是怎样的。(1)当然,“学科行为”这个表述有点抽象,具体一点说,问题应该是在哲学或中国哲学的名义下从事研究,是基于怎样的行业标准与规范进行实操?或者更直白一点,就是专业领域的研究者们怎么“做哲学”?而当问题被表述到这样直白时,就可以谈论AI的应用了。因为只要涉及“做”,不论什么学科都要有怎么去“做”的工程考量;那么AI作为当下最强劲的工程方案,对“做哲学”有无助益,就是值得思考的问题。(2)而本文选择中国哲学进行示例,正在于合法性质疑的存在反而有助于彰显“做哲学”在工程上的独立意义,因为中国思想是不是哲学,并不妨碍进行以之为对象的哲学研究,所以下文要谈的就是在实际研究中,AI能做什么?
工程视角:哲学家做什么
人们对“哲学是什么”有不同的理解,可能就在于这是一个纯粹的哲学问题,允许不同尺度的思考与谈论;但是,哲学研究是什么却不只是哲学问题,更涉及工程问题,因为对这个问题的回答未必决定性地依赖对“哲学是什么”的理解,却一定要观察被视为“哲学家”的那类人(无论是广义的还是狭义的)究竟在做什么,“做”正是一切工程问题的核心。
那么,就让我们从“哲学家做什么”这个问题谈起。这是个老问题,但若视为与“哲学是什么”层次不同的问题,则又是个新问题。因为多数情况下,“哲学家做什么”这个问题往往被伪装成“哲学是什么”的问题。比如人们常说哲学是理性的事业,但这与其说是来自对哲学本身的抽象界定,不如说是来自对哲学家做什么的经验观察,因为“事业”必须有诉诸实操的、可辨识的行动表征。而要谈论这些表征,先要将哲学家想什么和做什么区别开,因为哲学家所想的东西很不相同,但所做的事情却高度相似——那就是,无论这一群体在思想上有哪些不可调和的分歧,都无碍他们去“做”同一件事,就是为其所想的东西做论证。所以,无论对论证的理解是精确还是模糊,将“做论证”视为“哲学家做什么”的主要工作,因而视为“理性事业”的行动表征,大概是经验上最为显著的特征。就连存在合法性争议的中国哲学的领域,也时常能看到研究者对论证之重要的强调。这一重视论证的态度要追溯到冯友兰,他在为中国哲学研究开创学科范式的名著《中国哲学史》中,明确将哲学界定为依逻辑地讲道理。(3)而这与其说是对“哲学是什么”的界定,不如说是对“哲学家做什么”的界定。
借用冯友兰的说法,如果哲学家为其主张“做论证”就是“依逻辑地讲道理”,则哲学家做什么就能被进一步界定为“做证明”,或说是以演绎的方式讲道理。什么叫“演绎的方式”?逻辑学提供了两种特征描述,一是“必然保真”(necessarily truth-preserving),一是“一步一步”(step by step)。前者是对真值演算的描述,对象是句子及其关系;后者则不同,指的是从事真值演算的行动者展示其演算步骤的行为,所以更适合作为“理性事业”的行动表征。问题是“一步一步”地展示过程,这是不是必然保真的要求?诺瓦伊思在其对“演绎之根”的讨论中认为,步骤性实际是对话活动的认知属性,服务于理解、质疑、理性合作等目的,因此演绎不能是从前提到结论的“一步论证”;而必须展示过程,就并非必然保真的要求,而是多主体交互的行动要求。(4)我很赞同这种看法,并尝试为他所说的“一步论证”补充一个案例,即假设有一部自动演绎机,其输入输出只是真值,那么不难发现这部机器是否出错,无关于是否展示步骤,甚至不知道其内部运转是否有步骤。所以,将步骤性视为认知的属性是合理的,比如,要求某人展示其演绎步骤,通常是为了质询其做证明的有效性,这在数学考试中尤其明显(因为只写答案而无解题过程不得分)。那么回到哲学家做什么这个问题,如果“一步一步”是其“做什么”的行动表征,就能认为哲学家不是为演绎而演绎,而是为理解而演绎;因此在演绎的有效性之外,对论题与论证提出多样的认知诉求,如知识、信念甚至情感、体验等,就使得哲学家的理性事业超出了逻辑学家的保真事业。
但要进一步刻画哲学家的事业,还要看看科学或经验科学。对理解逻辑学家做什么来说,这不必要,因为逻辑学家对必然保真的关切会导致其排斥不能保真的东西,那就是经验,因为经验会出错,但逻辑不出错。因此在不出错的意义上,逻辑是科学,却不是经验科学(或主流科学),正统的逻辑学家也没有面向经验世界本身的认知诉求。经验科学家则不同,其虽然也重视在逻辑上做证明,但更重视在经验中找证据。因此面向经验的认知诉求就能将经验科学家的事业区别于逻辑学家。但问题是,哲学家也有面向经验的认知诉求,其与经验科学家的认知诉求又有何不同呢?一种简洁而流俗的叙事是,哲学家眼中的世界不仅有经验,还有“先于”经验、“高于”经验的东西,因此科学家关切的东西在哲学家的眼中只是世界的某个部分。20世纪的科学哲学中就有这种叙事,认为科学家要使世界的这部分或那部分变得可理解,但哲学家要“看整体”(eye on the whole);并且,哲学家虽明知自己不可能掌握全部科学知识,却仍然相信“有他自己的方式”来看整体。(5)回到哲学史,这是一种相当古老的叙事,就像亚里士多德在其《形而上学》中指出的,科学家研究一事物是什么的局部,哲学家研究全部。这个“全部”的意涵,正关涉“一事物”在哲学家与科学家眼中的不同形象。比如,亚里士多德宣称最重要的问题是去追问“一事物是什么或这个(是什么)”。但这不是一个问题,而是两个问题,因为“一事物”不同于“这个”,“这个”是具体的某物或经验对象,“一事物”却既不是这个、也不是那个,而是任一个或每一个,或者说“一事物”就是“全部”。那么,如果说“这个是什么”是一个科学问题,就应该说“一事物是什么”是一个正宗的哲学问题,其关注的不是局部世界的可解释性,而是整个世界的可解释性,这大概就是哲学家的理性事业不同于科学事业的地方。
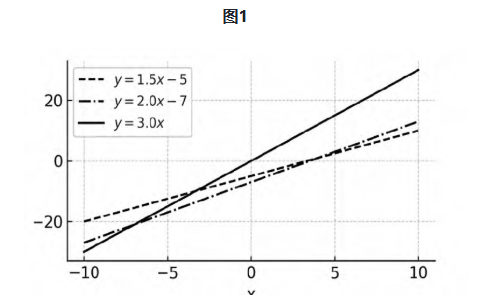
当然,“哲学家做什么”和“科学家做什么”有何不同,还能有更多维度、更细粒度的刻画,但将哲学事业描述为追求整个世界的可解释性,这与AI的应用最为相关。因为如果通用人工智能就是AI演化的最终目标,就有理由期待AI能在哲学家解释世界的理性事业中扮演角色。不过,要弄清楚AI能做什么,除了基于技术趋势的推测,也应该着眼于AI的底层逻辑。这时,就要将话题转向对世界的数学表示,因为这关联于对机器具备何种能力的定性式理解。现在,假设某个状态函数y=f(x)描述了世界的变化,x为当前世界的某种状态,y为x引起或造成的状态,其过程可简化例示为:
y=f(x)=2x+1
很明显,状态函数y=f(x)表明世界的每一种状态变化都是线性或匀速的,因此每一种变化的结果都可预先计算。如果这就是世界的实情,那么AI大概率能替代哲学家解释世界的理性事业,方式就是用其他状态函数如h=g(x)精准拟合(fitting)世界本身的y=f(x):
h=g(x)=wx+b
不严格但更直观地说,这一拟合就是建模(modeling),是通过大量数据的迭代学习,使参数w与b的值逼近状态函数f(x)=2x+1的两个常数(图1)。不过,至少在切身感受上,我们所见的世界并不总是像以上线性函数描述的那样确定,而是让人觉得充满变数与复杂性(这并非对世界本身来说),所以更适合以非线性的状态函数进行描述,比如:
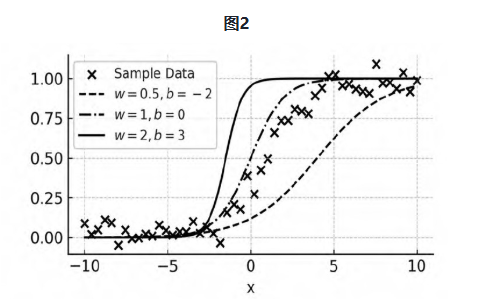
y=f(x)=sigmoid(2x+1)
这时,随着状态x的变化,y的变化并非匀速,而是由于sigmoid(激活函数之一)的映射时快时慢(斜率不同),也就是说,世界的变化不再能由线性关系预先推定。这样的复杂世界当然更能引起哲学家的兴趣,但AI同样可以用状态函数h=g(x)进行拟合:
(x)=sigmoid(wx+b)(6)
这一拟合过程要复杂得多,关涉神经网络的前向传播、反向传播与梯度下降算法;但目标仍然是更新w与b的参数值,使之逼近真实状态函数f(x)的输出(图2)。因此就能说,如果世界状态的变化是非线性的,AI也将比哲学家更有能力做预测(但不是做解释)。
所以当哲学家还在为解释世界的理性事业奋斗时,工程师们已经有信心去建立世界模型,如OPENAI推出的SORA模型,宗旨就是真实世界的重新建模;谷歌DEEPMIND最新推出的世界模型GENIE3更在一致性(历史可保留)与交互性(现实可构造)上取得了重要突破。但即便如此,仍然不能忽视的语境差异是AI世界模型所拟合的主要是物理世界及其规律,哲学家眼中的世界却并不仅限于物理,还有非物理的内容,比如思想。因此工程师所追求的世界模型未必能引起哲学家的重视。不过,也不是所有哲学家都认为世界不仅是物理的,还有非物理的方面。比如当代心灵哲学中有一种强势的唯物论,认为将一切都说成“物理的”在什么意义上都正确;(7)这也就意味着精神、价值、意义等凡是不能实物化的东西最终都能还原到物理领域。但严格说来,这种来自心灵哲学的物理主义很难被视为“真正的”哲学观点。因为哲学家解释世界,也要解释其所使用的解释语言,所以将一切都归于“物理”,从哲学家的视角看,就会使“物理的”这个词本身变得晦暗,甚至陷入神秘,因而不符合理性事业的要求。其次从现实看,被称为“心灵哲学家”的人也并不全是哲学家,而是有相当比重的认知与神经科学家,这使得“心灵哲学”的“哲学”二字带有相当的实用意味,即科学家只是为了谈论某些一般性或超出实验限度的问题时,方便地将其观点称为“哲学”。但回到哲学的正统谱系,虽然哲学家在其解释世界的理性事业中的确存在很多分歧,但这个世界不仅是物理的,还有非物理或属于思想领域的东西,仍然是一个公约数。
因此,考虑“哲学家做什么”这个问题时,使世界具有可解释性的哲学任务就不仅是使物理世界可解释,也包括(甚至主要是)让思想或精神世界可解释。因而当评估AI在这项哲学事业中扮演何种角色时,首先就要问,思想——如果假定为非物理的——能否给予某种表示,让AI在表示学习中进行拟合,尤其是基于神经网络进行建模?
思想建模:AI能做什么
除了物理领域的世界模型,有无可能训练某种思想模型,这当然还是工程问题,要在实际项目中进行评估。但从工程视角看问题并不是要阻断哲学思考,因为被称为“思想”的东西是什么,如果不能提供某种哲学上的理解作为监督信号,就很难指望AI学到什么。可问题依然是,不同哲学家对思想是什么会有非常不同的理解,如果暂停目前的讨论,回头辨析何谓思想,无疑是代价高昂的做法。因此回到“哲学家做什么”这个问题,与其讨论他们对思想本身的理解,不如看他们怎样使其所认为的思想具有可解释性。
这时,值得注意的是一种平凡的见解如何在哲学上获得非凡的阐发,这个平凡见解就是语言表达思想,思想见诸语义;但哲学家的观点是,被称为“思想”的东西并不涵盖句子语义的全部,而仅是语义中能被普遍断定为真或假的东西。由此,语言与思想的关系问题就被转化为语义和真值的关系问题,并成为当代语言哲学的核心问题。这当然超出了人们对语言表达思想的常识理解,但也恰恰表明在哲学上,从语义的可解释性到达思想的可解释性,是“哲学家做什么”的一个典型案例。而这也正是评估AI用于思想建模的好案例,因为自然语言处理正是AI主要的用武之地,所以就能从AI对语义的理解入手,逐步评估其对思想的建模能力。但在实施之前,有必要提醒读者注意AI领域大量使用隐喻修辞的情况。在工程上,怎么做优先于怎么说,隐喻的使用主要是避免陷入复杂概念辨析降低实践效率的策略。比如之前提及的“学习”,无论是传统机器学习还是现代深度学习,主要是更新权重参数(w)与偏置参数(b)。同样,说到AI对语义的“理解”时也只是为语义提供数学上的向量化表示,包括基于统计的语义编码、位置编码与注意力机制等。因此最简单地说,AI对文本的理解在性质上不是生物的,而是数学的,是将“语义”转化为一串数字(n维向量),这一过程(嵌入)使得文本语义具备了可计算性。因此,如果忽视对机器来说的“学习”“理解”等词汇的修辞属性,很可能使人将AI建模类比于对生物学机制的模仿,而忽视其本质是数学建模,进而就可能产生种种担忧。当然,AI虽不是在模拟理解语义的生物学机制,高质量的向量表示仍可以将人类视角下不同意思的表达区别开,甚至更精准。
说到这里,就能回到中国哲学的研究领域,基于AI对文本语义的“理解”来构建思想模型。但这里主要关注古汉语文本,因为中国哲学研究的大宗是古典中国思想。而就目前来看,已有不少面向古汉语的通用语言模型,能为词与句提供优质的向量表示。但仅仅如此还不够,因为适合思想建模的AI不仅要能理解古汉语,还要能理解古典中国思想特有的概念与命题(如“天”“道”“心”“性”或“仁者爱人”“万物一体”等),并能对不同概念的关系、不同命题的关系进行满足研究需要的深层次提取。因此在工程上,需要在专门的思想文本上训练AI,第一步是对中国哲学研究通常关注的思想术语和思想主张进行语义建模,第二步则是在语义建模的基础上进行关系建模,让AI有能力刻画不同概念或命题所具有的深层联系。这两步,就是以下所说的基础建模与进阶建模。
1.基础建模
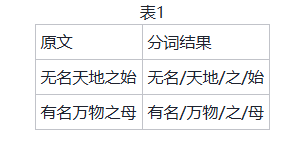
在基础建模的阶段,让AI理解古代思想文本中的专门术语和语句,核心就是具备两种能力,一是辨别词义,另一是辨别句义。当然,本文要论述的是AI能做什么,而非如何让AI这样做,所以此处与后文将省略技术路线,仅展示其经过训练的能力是怎样的(因此要特别申明的一点是,论文后续所有诉诸模型推理的结果仅为演示“AI如何应用于中国哲学研究”,不是要用AI解决中国哲学研究的某个实际问题)。(8)而对上述辨析词义的能力来说,可在分词任务中进行观察,因为要检验AI是否理解思想文本的语义,首先就要看是否能将不同的语词(尤其是特定术语)区分开。这里提供的案例,是以自建分词模型对《老子》第一章“无名天地之始,有名万物之母”进行分词(表1)。在古代注释与现代研究中,这句话通常被断句为“无,名天地之始;有,名万物之母”。(9)在中国哲学的主流研究中,这种断句尤其受到重视,因为仅就字面意思给人的感受来看,“无”和“有”这两个词汇确乎很能显示中国思想作为哲学的抽象性或哲学性。但随着出土文献与传世文献研究的深入,也有新看法主张《老子》首章这句话应以“无名”“有名”进行断句,而AI在大量思想类文本的训练后提供的分词结果正好为新的断句方案提供了支持。当然,如前所述,AI并不是按人类的方式理解语义,其不将“无名”或“有名”切分为两个词,主要是基于文本向量进行的概率预测,所以也应明晰的一点是来自AI的支持乃是基于计算的数据支持。问题则是如何看待这种支持,其是否能被视为依据?这可能与人类研究者的信念相关,比如,某人认为AI对文本语义的计算是可信的,便可能接受其支持;但若他在根本上就怀疑语义的可计算性,更不相信语义能被向量化,便不会将AI的输出视为依据。可即便如此,信与不信也并非判断AI的处理结果是否可用的全部依据,因为AI虽然不是像人那样理解语义,但只要其辨析语义的结果是可验证的,甚至某些结果比人类的语义辨析更精准,那么从工程视角看,就不妨碍宣称AI理解语义,虽然这只是隐喻。
那么仅从结果来看,AI到底有无辨析语义的能力呢?我们把视角转向句子。以下案例是以《庄子·齐物论》中的“天地与我并生而万物与我为一”为锚点语句,使用自建的语句相似度计算模型,(10)再从先秦到魏晋的子学文本中查找与之意思相关的语句。结果显示(表2),AI找到的第一个句子就是锚点句自身(余弦值为1.00),这表明AI能识别这个句子自身的意思,否则就不可能通过语义(向量)找到它。再看第二个句子,语义相似度降到0.87,正在于“天地与我并生”被描述为“类”,这是锚点句没有的意思。但0.8以上仍然是强相关,这意味着查询句只是对锚点句的语义延伸或增量诠释,而非显著转变。第三个查询语句则不同,虽然“天地运而相通,万物总而为一”和“天地与我并生而万物与我为一”的差异仅是前一个句子没有谈论“我”,但余弦相似度降低到0.71,显示语义明显变化,这或许能启发研究者去思考《庄子》的思想旨归是否不在谈论“天地”与“万物”,而是在“我”?由此看,AI对语义的理解,虽与人类的生物学机制不同,但同样能辨别语义的同与异;而其价值除了可以帮助研究者分析哪些表述的变化造成了语义的差别之外,还可以借此评估不同表述在句子语义中的权重。所有这些助力都来自给出了度量数值(余弦相似度)——其令文本语义成为可计算的,意味着语义分析能被纳入定量研究的范畴,而不仅靠研究者的个人理解。

注:cosine范围为[-1,1],0.5以上存在相关性,0.6—0.7相关性显著,0.7—0.8相关性较强,0.8—0.9强相关,0.9—1.0仅有极细微差异。
2.进阶建模
基于分词和相似度计算,AI已经可以对古汉语思想文本的语义进行拟合,但要满足思想研究的需要,还需在此基础上做进阶建模,并同样能从句子和词汇两个量级展开。在句子级别,单纯字面相似度计算还是初步的,因为思想研究中常常要挖掘不同主张超出字面的深层联系。对此,或可用图神经网络(GNN)建模句子关系,把语句表示为图中的节点,用节点之间进行信息交互的边来表示句子关系。但传统图神经网络的局限是只能在两个节点之间建边,就是说,只能刻画成对句子的关系,而要讨论多句子的复杂关系,超图网络(HGN)更有优势,其允许多个节点语句共享同一条边,也即超边,是对多句子关系的高维度表示。
为说明这种建模方式及其相对于字面相似度计算之不同,可继续以“天地与我并生而万物与我为一”这个道家主张为例。调用训练完成的超图模型,(11)能在诸子学文本中找到与之构成联系的多个语句,也即共享同一超边的多个节点。模型会对每个节点语句计算其与锚点句构成关联的概率;以隐喻的语言说,这些概率就是AI对不同句子是否和锚点句相关的确信程度。但要点是,被确信存在的语句关联并不仅限于字面相似,相反其字面意思往往差别显著。如表3所列,模型最能确信和“天地与我并生而万物与我为一”构成关联的“彼方且与造物者为人而游乎天地之一气”(gid: 25859)这句话(出于《庄子·大宗师》),其与锚点句的字面相似度并不高(余弦值0.644)。但在超边结构中,却是模型置信度最高的节点(概率0.8367),就是说,超出字面语义的关联最为显著,其或可解释为:(1)锚点句说的是“我”,节点句说的是“彼”,但都是道家推崇的得道者;(2)锚点句说的是“天地与我并生”,节点句说是“游乎天地之一气”,但都是得道者与事物世界和谐一致的表现;(3)锚点句说是“万物与我为一”,节点句说是“与造物者为人”,但都是在描述不以物、我绝对相分的得道境界。但要注意,(1)—(3)并非AI提供的解释,而是研究者基于学科先验知识的解释,并且还可能有其他解释;所以更确切地说,AI可用于发现语句超出字面意思的关联(而且不同参数设置下可能发生变化),但这种关联能被称为“深层”的关联,恰是指需要通过人类研究为其提供可解释性,比如将以上(1)—(3)解释为意思不同的语句在主题或论域上的深层关联。

在中国哲学或人文学科的其他专业领域,我相信“AI发现+人类解释”将是未来人机合作进行高阶研究的主要形式。这一方面是说,至少在思想领域,依赖人类专家的创造性解释还无法被AI真正取代(充其量是模仿);但另一方面也是说,AI的发现能为增强人类解释的创造性提供重要启发。这不仅体现在句子级别的进阶建模中,也体现在词汇级别的进阶建模中。比如,AI不仅用于分词,更能在分词基础上挖掘概念语汇的内在关联及其演变模式,这将为中国哲学的概念史研究提供新视角。技术上,基于超图网络的建模方案仍然可行,只需要将超边节点从句子替换为词。(12)但也要考虑语词不同于句子的独特性,尤其是,不同语词构成的组合可能在不同上下文中高频再现,但句子的共现往往更稀疏。所以建模语词关联时就要考虑同一语词组合(限定为2元或3元,距离窗口不超过5个分词片段)出现于不同上下文(统计窗口不超过1000个样本行)的语义关联如何变化。(13)
这里以中国哲学研究中极受重视的“道—物”关系为例来作说明。在从先秦到魏晋的子学文献中,基于现有模型权重和预设的样本集次序,(14)“道”与“物”在同一上下文中关联出现了近315次,概念超图模型则在每一处上下文中输出了二者构成关联的语义强度(均值0.4864,最大0.9946,最小0.2363),并能由此判断其关联呈现下降趋势(图3)。有趣的是,对强度曲线几处峰值位置的节点进行采样,能发现“道”与“物”多是在有关世界秩序的抽象论说中具有语义上的强关联(表4)。因此这一概念组合的强度总体趋于下降,是否意味着早期中国思想对抽象领域的兴趣逐步削弱?或者说,是否思想家们越来越关注现实?就是值得研究者进一步核验的问题。但这里我们更关心的不是学术观点,而是研究范式,即AI对语词关联及其演化趋势的建模将为研究者提供另一形式的概念史,其不同于传统人工梳理的概念史,而是数字概念史,后者的核心理念即概念的演化是可计算的,因此即便是人文领域的概念研究也能被纳入定量研究的范畴。当然,数字概念史不仅是方法,更是如何看待概念史的一种视角。仍以“道”概念为例,既然其强度数值在不同上下文中总是变化,就意味着孤立的概念没有历史,只有概念之间的关联或概念网络才有历史。如图4所见,按现有样本集的次序设置,事件曲线模拟了“道”概念从先秦到魏晋与其他概念的关联变动最为显著的11个阶段或事件(灰色区间)。选择查看曲线两处峰值位置(事件3、事件5),会发现以“道”为锚点的概念网络中,有些概念关联依旧保持,但更多是新的概念关联的形成,其中就包括以往研究者讨论最多的“道”与“自然”的关联(图5、图6)。所以说,孤立的概念没有历史,只有概念构成关联的网络才有历史,而这正是基于AI追踪概念演化带来的观察概念史的新视角。
图3道—物|Segmented Trend (ruptures)
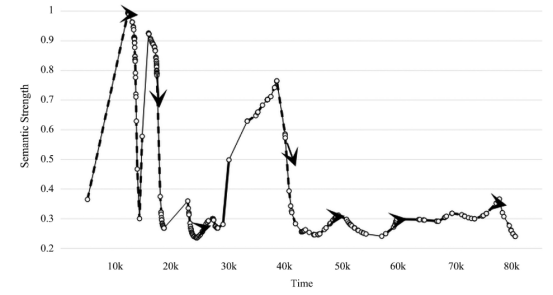
图4事件得分曲线event_score(t)
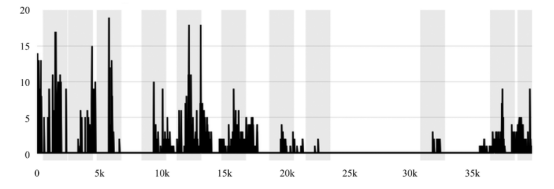
图5 事件3对应概念网络
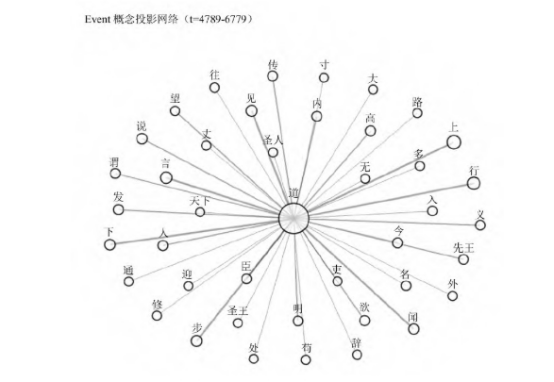
图6 事件5对应概念网络
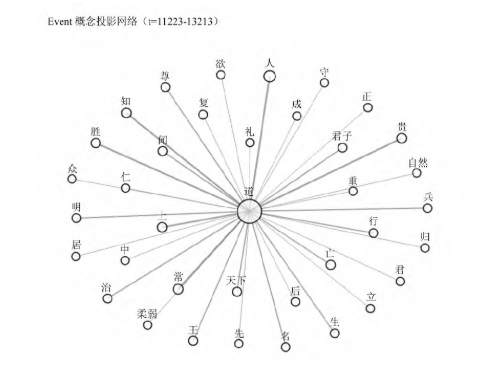
表4 图3曲线峰值对应的样本

3.哲学大模型
以上谈论AI应用于中国哲学的研究,主要涉及小参数量的自建神经网络(Transformer编码器分支),还没有谈及当下最受关注的大语言模型(LLMs)。后一应用方向之所以重要,在于大模型以其数以百千亿计的参数量,在各类任务中展现出强大的生成能力,为通用人工智能带来希望。但即便某个大模型在通用领域表现出色,在专业领域却很难“拿来就用”,需要对其进行面向专业数据和专业要求的微调(如SFT)。目前,笔者已经微调并部署了辅助中国哲学论证研究的专业模型。(15)以《公孙龙子·白马论》阐述“白马非马”的文字为例,能看到模型是从图尔敏模式、语用论辩和修辞学三种主流论证分析框架来刻画其说理过程(表5)。中肯地说,这些刻画已经在一定程度上体现出论证研究的专业性,比如对论证要素的提取、对论证阶段的划分与对论证语言的分析,是符合专业需要的结构化输出。
但要特别指出的是,以上所见大模型的应用与前文自建模型的应用场景非常不同,不是从思想文本提取数据,为研究者的解释提供基础,而是直接生成解释,因此人机合作的模式就发生了倒转,从如何用AI对文本的计算来驱动研究者做解释,变成如何用研究者提供的材料来驱动AI做解释——前一种人机合作的终端是人,后一种合作的终端则是机器。这两种人机合作孰优孰劣,还需要时间检验。但对充当后一种人机合作之基础的生成式AI来说,其面向思想研究的应用虽然可行,仍应注意的却是:生成式大模型面向专业领域的应用,如果真要从聊天工具变为生产力,不仅要有领域知识的监督微调(低参或全参),更要求监督信号即领域知识本身具有相当的客观性与可公度性,如此才能指导模型做出正确的专业判断。在这个意义上,也可以说越能提供标准答案的学科,大模型的应用空间越大。但人文学科并非如此,这倒不是说从人文研究取得客观可公度的领域知识不可能,但至少多数情况下,人文研究不是为了给出某个问题的唯一正确解。所以即便是在专业数据上经过微调的大模型,其所生成的内容也只具有专业上的参考价值,却不能作为依据或证据来使用。鉴于此,笔者更倾向在专业研究中优先应用前述建模文本语义的小模型,这不仅因为小模型可以在专业领域集中训练,避免大数据的污染;更在于让AI发挥作用,首先应该是追求为哲学或其他人文研究确立可公度的数据基础,而对小模型的构造更有望达成目标。
表5

不过,这并非否定大模型的应用价值,因为用大模型生成的内容做参考,仍然对人类研究者有启发意义。而在实践中,笔者发现,利用大模型的生成能力提升小模型推理结果的可解释性,即建构一种大小协作的AI工作流,是建构这种启发式研究的路径之一。(16)比如,先用进行相似度计算的小模型对文本做聚类(使相似的文句在向量空间彼此靠近,使不相似的彼此远离),在揭示其底层数据的特定结构之后(图7、图8,这是基于特定算法参数的结果,不同的设置会不同),将每个聚类簇送入大模型进行主题阐释(表6),会非常有助于拓展中国哲学研究的取材视野与问题意识。比如,对《释名》这部早期字书进行上述大小协作的处理,将启发我们思考字典在中国传统文化中扮演的角色。因为在大模型对所有聚类簇的解释中,不难看到字书中也有不少思想性主题(表6),所以,如果大模型的这些解释能通过人工校验,就意味着字书在中国古代是否仅有工具书的性质,是否也是中国古人整理其世界知识、提炼其抽象思想的一种结构化形式,将成为一个值得认真研究的问题,当然也可能被看作以往中国哲学研究处理不足但很值得尝试的新方向。
图7 小模型聚类
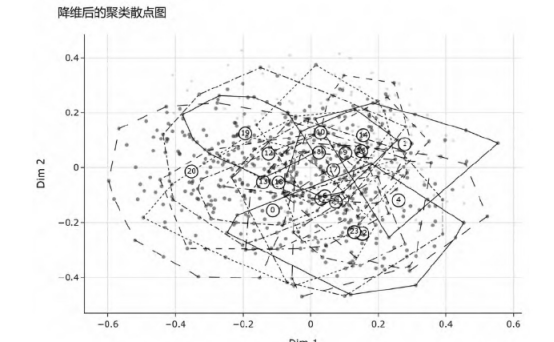
图8 小模型聚类
表6 大模型解释,以聚类簇5、6为示例

未来预期
以上,为说明AI应用于中国哲学研究的可能性,展示了如何从思想文本的语义建模实现思想建模,也延伸谈及了哲学大模型的落地应用。要强调的是,这些仅是如何使用AI的操作示例,而非可普遍化的技术路线。但换个角度看,评估AI之于哲学研究的价值,可能更需要这类实际示例,而非纯理论的说明,因为无论就高速的技术迭代来说,还是就人文学科在总体上的疏离来说,我们都还处于探索阶段。当然,仅就前文呈现的案例来说,有理由设想AI的引入能为哲学研究、中国哲学的研究乃至广义的人文研究带来三项收益。
1.效率。
在以工程科学为建制模板的现代大学中,文科尤其是人文研究遭受质疑的一个主要方面就是其知识生产的效率低下。因为以个人兴趣和地方性知识为主导的人文研究,包括哲学在内,不可能与自然或工程科学的协作型研究在效率上形成竞争,甚至速度与质量在人文研究中成为不可兼容的指标,慢研究往往是好研究的题中之义。但正如前文示例,利用AI面向超大样本的计算使中国哲学的研究能以宏大思想时空为作业单元,因此又快又好的研究不再是无法企及的。
2.客观性。
包括哲学在内的人文研究遭受诟病的另一方面在于其研究者相较于科学家更易受特定立场或个人偏好的影响,产生分歧和争论的概率更高。将此视为缺陷并指责文科,固然是对世界的复杂性缺乏认知的表现;但这种“无知”其实也提出了值得严肃对待的问题,就是有没有可能使文科,尤其是论辩最为激烈的哲学,在研究的基础或出发点上更有客观性,以便研究者不被虚假问题意识误导,将精力放在更值得论辩的话题上?我认为,至少在文本研究这一人文学科的主要作业领域来说,基于AI的语义编码和特征提取有助于建立客观的、可公度的基础。
3.创造力。
AI的发展最可能引起担忧的一个方面是其可能替代人类智能。但若连功能最为强大的生成式大模型也不能从真正稀疏的素材中进行生成(不能“无中生有”),便无需过多想象来自AI的威胁,(17)因为至少在性质上,AI仍是工具,只是这个工具看起来比以往人类社会的任何工具都强大,能在许多领域成为人类的代理者(agent);但代理者仍是工具,而非工具的使用者(user)。当然,并不排除AI在将来会出现从代理者到使用者的质变,但就当下来说,这仍然是科幻,而真正值得思考的现实问题是,AI正在且即将完全取代计算领域的人工作业,这对人类智能意味着什么?一种乐观但合理的推测是,AI的应用是对人类智能的一种解放,使人的智力资源可以更多投入到那些真正需要创造力的领域,其中就包括个性化的人文研究。
论述至此,论文期待展示的其实不仅是在中国哲学的研究中AI能做什么,更是对整个人文学科来说AI能做什么。但对后者来说,以上谈及的效率、客观性与创造力三点更是探索性的评估,有待在多学科协作的背景下开展更多的项目实验,本文提供的则仅是来自哲学学科的示例;甚至就限定在哲学领域内,这些示例也是局部性的,不具有技术路线和作业指南的普遍意义。但即便如此,似乎仍然能对AI应用于哲学研究的前景做两点宽泛的预测。首先是,基于AI对思想文本的语义建模,可能会进一步强化哲学与实验科学的深层联系。这种“强化”将远超目前哲学上设想的所谓“思想实验”的尺度,而是真的会把很多工程手段与定量分析引入哲学研究中。但这一点在前文的建模实例中已有展示,此处不再赘述。更重要的是另一点,即随着AI面向专业研究的应用落地,除了会强化哲学与实验科学的融合,也可能弱化哲学研究与经验研究的分界。这种“弱化”同样远超传统哲学中对“先验/经验”“分析/综合”之分的讨论尺度,而是可能将哲学家解释世界的努力真正引向现实领域。因为哲学家谈论AI,无论是否恰当,这件事本身就非同凡响,即相比于传统哲学反思聚焦于先验领域的特征,对AI的哲学反思则显著地指向经验,指向人们的现实生活。比如,时常能听到一种关于AI造成危机的哲学预警,其基本句式是“如果不对AI加以限制,未来将对人类生活与人的存在带来何种问题”——但这与其说是正统的哲学反思,不如说更接近经验科学中面向未来的危机预警,与气象灾害预警或金融风险预警在性质上并无不同,却与面向先验领域的哲学反思面貌迥异,至少显得不太“纯粹”。而这也就是说,无论哲学家对AI抱有何种态度,哲学研究与经验研究的界线已然在AI这个话题上变得模糊。
【注 释】
(1)笔者曾致力阐述“中国哲学作为方式”的观念,就是强调这种问题意识的转换。参见李巍:《合法性还是专业性:中国哲学作为“方式”》,《江海学刊》2019年第2期;《中国哲学是什么?——一种面向现实的思考》,《社会科学战线》2024年第6期。
(2)虽然缺乏将AI应用于哲学研究的工程实操,但已有不少将二者结合起来的积极设想。稍早如探讨亚里士多德的美德伦理学如何应用于设计道德机器,参见Nicolas Berberich,Klaus Diepold,The Virtuous Machine-Old Ethics for New Technology,//arxiv.org/pdf/1806.10322。近年来,相关讨论则聚焦大语言模型的哲学应用,比如为全猪论题(Whole Hog Thesis)进行哲学辩护,该论题主张如ChatGPT等大语言模型是充分发展的语言与认知代理,其能有意义地使用语言做断定、问问题、提供建议和提要求,而对语言的使用反映其具有完整的认知状态,如知道某物、相信某物、期待某物等。至于大模型的缺陷,如幻觉、推理谬误等,并非其完全不具备认知代理能力的表现,而是与人类认知的缺陷有可类比性,参见H.Cappelen,J.Dever,Going Whole Hog:A Philosophical Defense of AI Cognition,//arxiv.org/pdf/2504.13988。再者,关于如何减轻大语言模型的幻觉,一种哲学上的尝试是引入拉康的语言哲学与心理分析来构建anchor-RAG框架,参见Qiantong Wang,From “Hallucination” to “Suture”:Insights from Language Philosophy to Enhance Large Language Models,//arxiv.org/pdf/2503.14392v1。此外,在社会学调查中发现的中国社会相较于欧美对AI技术的发展有更高的接受度和更乐观的未来想象,也有论者尝试从文化传统尤其是中国古代哲学思想的“影响”中找原因,比如来自儒道佛的非人类中心主义道德观使得西方关于AI造成主体性沦陷的焦虑在中国的社会心理中并不显著,参见“How Chinese Philosophy Impacts AINarratives and Imagined AI Futures”,Imagining AI:How the World Sees Intelligent Machines,Stephen Cave,Kanta Dihal,eds.,Oxford:Oxford University Press,2023,pp.338-352,//doi.org/10.1093/oso/9780192865366.003.0021。与中国哲学关联度最高的研究是《哲学与文化》2024年第11期刊发的《儒学与AI专题》(黄信二、黄燕强主编),该专题由1篇导言与6篇论文构成,既从儒学的视角观察AI的未来发展,也从AI的视角思考儒学的自我更新,因此呈现出一种具有交互性和建设性的积极问题意识。
(3)参见冯友兰:《中国哲学史》(上),《三松堂全集》第二卷,中华书局2014年版,第16—17页。
(4)参见C.D.Novaes,The Dialogical Roots of Deduction:Historical,Cognitive,and Philosophical Perspectives on Reasoning,Cambridge:Cambridge University Press,2021,pp.6,65.
(5)参见Wilfrid Sellars,Philosophy and the Scientific Image of Man,in Robert G.Colodny,ed.,Frontiers of Science and Philosophy,Pittsburgh:University of Pittsburgh Press,1962,pp.35-78,//www.ditext.com/sellars/psim.html。
(6)这是对神经网络逼近定理的简化表达,以便非专业读者理解原理。原始数学表达参见G.Cybenko,“Approximation by Superpositions of a Sigmoidal Function”,Mathematics of Control,Signals and Systems,Vol.2,No.4,1989,pp.303-304。
(7)参见[美]斯蒂芬·P.斯蒂克等编:《心灵哲学》,高新民等译,中国人民大学出版社2014年版,第76页;[新西兰]戴维·布拉登-米切尔等:《心灵与认知哲学》,魏屹东等译,科学出版社2015年版,第203—205页。
(8)这一方面是因为建模方案还在不断更新中,不同方案下的计算结果会有差异;另一方面,是因为中国哲学学科还没有建立工业级的公开数据集,无法对模型性能进行客观评估。但即便如此,仍可对必要的基本建模信息通义说明如下,后文不再重复:1.数据集:本研究使用的数据集为自建数据集,分别是用于训练小型神经网络的“中国哲学合集”(持续更新中)与用于大模型微调的“中国哲学论证数据集”(持续更新中)。(1)“中国哲学合集”选择了本学科最常涉及的古代经典并进行了初步的人工审核,规模12,654,779字,以txt存储,每行一句,不超过256字。鉴于古文的现代标点、章节号、标题存在不一致,为避免噪音,统一移除全部标点、章节号与标题。同时,基于长度限制256字,先用大模型(基于schema约束和强校验)按语义分行,再由人工审核,但仍然难免误切;(2)“中国哲学论证数据集”每条语料为从古籍中选出的一段论证文字,以先秦诸子学文献为主,目前仅包括指令集13654条,蒸馏集21048条,以jsonl格式存储。2.模型组件:分为自建小型神经网络与大语言模型两类。小模型是以面向古汉语文本的Chinese Ancient BERT(Large)为基础(Hugging Face用户zhuimeng,shaonian发布,URL://huggingface.co/zhuimengshaonian/bert-ancient-large,2022),具体包括分词模型、相似度计算模型、超图模型等,详见下文。以上部分模型组件已上线试运行(//qwzs.lzu.edu.cn),属于“齐物智算·中国哲学深度学习模型群”组件。论文中的部分结果可在线上进行复现,但因为建模方案和数据集仍在持续更新中,结果可能出现浮动。不过,本文并未设置任何追求复现的工程目标,所以凡是诉诸模型推理的结果仅用作如何以AI辅助哲学研究的使用示例。
(9)在“中国哲学合集”上微调古文BERT最后4层并按训练集0.95、验证集0.05、最大行长256训练边界分词头,同时以hanlp为局部教师模型并引入自定义的中国哲学标签字典,目的是让模型更适合中国哲学专业语料的分词任务。
(10)在“中国哲学合集”上微调古文BERT的最后4层,按训练集0.9、验证集0.1、最大行长256训练语义表示头。利用整行的平均语义向量和首字符向量来确保稳定的语义表示,并用余弦相似度判断任意文本行在向量空间是否接近,目标是让模型更适合面向中国哲学语料的命题检索、比对等任务。
(11)在“中国哲学合集”上按训练集0.9、验证集0.1、窗口最大100行设置,训练时将不同的本行作为节点,用超边建模不同的本行的语义关系,嵌入维度1024、4层、8注意力头,训练目标是让模型自行捕捉多句子超出字面语义的结构性联系。但为使结果具备一定可解释性,引入了自定义的中国哲学标签字典进行监督。
(12)词汇的识别来自分词模型的输出。训练时,将“中国哲学合集”按训练集0.8、验证集0.2划分,通过余弦相似度计算概念2元组与3元组的每次出现的组合强度。
(13)此外还要特别强调的一点是,用这种方式追溯概念组合的历史演化,只是以文本序列作为时间序列的近似表征,因为中国古文献的先后次序存在诸多不确定性,早期中国文献尤其显著。所以合理的建模目标应该只是让AI对任意概念组合的每次出现计算出确切的强度数值,但允许对强度变化趋势的判断存在不确定性。
(14)从“中国哲学合集”中截取先秦到魏晋部分,文本次序不变。
(15)该模型基于qwen3:32b,在自建“中国哲学论证数据集”上进行LoRA SFT微调,分指令微调与蒸馏学习两阶段,r=64,alpha=128;批次2,梯度积累16,训练轮次2。
(16)这一大小协作的管线已在“齐物智算”发布的组件中落地,包括文本聚类组件(//qwzs.lzu.edu.cn/cluster/)与命题语义计算组件(//qwzs.lzu.edu.cn/semantic/)。
(17)即便AI的“看起来”能完成不少高端的智慧创作,如艺术、审美等,但这不是真正意义的“创作”,而是基于训练权重和奖惩机制的预测。
对《中国哲学:AI能做什么?》一文的审查报告
赵汀阳
李巍教授的论文《中国哲学:AI能做什么?》是一项前沿研究,其前沿性在于:(1)以AI为工具对中国传统哲学或古代哲学(文中“中国哲学”的实际所指)的语言表述进行分析,以我所知,应该是首例。确实已经有利用AI对其他文献例如古代诗词进行分析的实例,但似乎未见对古代中国哲学文献进行的AI分析。李巍教授有熟练应用AI的能力,因此得以开拓了此项研究;(2)此项分析所用的AI属于语言大模型(LLM),是目前最适合分析文献的人工智能工具,因此,李巍的分析与AI发展同步并且是最优配置。其他类型的前沿AI,比如李飞飞的“世界模型”(WM)最近据信已经取得初步突破,实质效果还有待证明,但“世界模型”并不非常适合文献分析,也许以后有所帮助,尚未可知。类似的,尚未突破的具身智能也不太适合文献分析。因此,文献的AI分析工具以目前情况而言就是LLM;(3)李巍教授提出对中国哲学使用“工程视角”来进行“思想建模”,从他进行的若干实例分析来看,显示出很有潜力。从语素链接的概率情况来“尽量接近”古人的用意,应该是一种可行方法。这种努力涉及一些语言哲学的问题,很值得讨论。
首先,从古代文献里的语素链接的概率情况去推测古人的真正用意,这个思路的方向是有道理的,至少可以获得后期维特根斯坦理论的支持,即“意义在于用法”的原则。或许每个人在使用一个概念时,在心里有某种“真正的”意思。但维特根斯坦对此比较怀疑,内心隐藏的意义需要表达为私人语言,可是私人语言已经被证明在语言学上不可能成立。也许未必所有人都同意维特根斯坦对私人语言几乎无懈可击的否证,因此可以退一步说,即使语言在心里确实有某种私人意义,但此种私人意义无法在公共语言里呈现出来,或者说在任何情况下都是不可见的,因此等于无意义。人们只能看见在公共语言里的意义,那些公开可见的意义就在用法里,而用法能够确定的意义就表现为大概率的语言链接。在这个意义上,李巍教授的AI分析是有效的。不过,也存在一个局限性,那就是,保留下来的古代文献数量非常有限,其中能够呈现的语言链接也就很有限,在链接如此贫乏的条件下产生的概率,严格地说,很难保证充分有效性,但肯定有某种参考价值。
另一个相关问题是,思想家们的观念很可能更为个性化,这意味着,思想家在使用通用概念时或可能有一些与众不同的用法。思想家选择特殊化的用法,甚至故意使用有点奇怪的词汇,是有其理由的。比如在普遍媒体化的当代,大量学术概念已经在社会化滥用尤其是在商业的滥用中被败坏了,以至于学术概念有时候会显得庸俗不堪,于是思想家时而不得不选用一些少见词汇,例如“千高原”或“皱褶”之类。不过,在古代,这种需要去故意使用特殊用法或词汇的情况应该还不多。无论如何,思想家的那些特殊化意义会被概率算法所淘汰,毕竟大概率意味着通常性。文中关于“无名天地之始;有名万物之母”的例子就是一个疑难。到底是“无名,天地之始;有名,万物之母”还是“无,名天地之始;有,名万物之母”?恐怕AI并不能给出可信答案。更深入的相关问题是,在语言用法的大概率中形成的“通常用法”也有其突出的优点,那就是含义趋近明确性。维特根斯坦之所以故意选用最日常的语言来表达最艰深的思想,就是因为日常语言的意义已经在大量交织用法中被基本确定,相当于最趋近稳定的函数值,因此把误读概率降到最低。相反,那些生僻或古怪词汇由于缺乏足够多的语境约束而更可能产生误读或误解。
总之,正如李巍教授预期的,引入AI的助力,有希望对含义相对比较含糊的中国传统哲学实施清晰化,当然,可能只是某种程度的清晰化。期待李巍教授在接下来的研究里有更为精彩的推进。
(编辑:邓莉萍 审核:陈江进 终审:刘慧)